Predicting Product Labels Using Random Forest Classification in Python
Introduction
In this article, I’ll walk you through a simple yet effective project where I used a Random Forest classifier to predict missing product labels in a store sales report. The dataset I used for this project is available on my GitHub repository. You can also see the full code on my Google Colab notebook.

Project Overview
Missing product labels in sales data can hinder analysis and decision-making processes. To resolve this, I implemented a Random Forest classifier using Python to predict and classify these missing labels accurately. This ensures that the data is complete and reliable for further analysis.
Dataset Overview
The dataset consists of two parts:
- Sales Data: Contains all labels, used to train the model.
- Data to Predict: Contains entries with missing labels to be predicted by the model.
The dataset includes the following columns:
- Date: The date of the sales entry.
- Product: The product name (target label).
- Quantity: The quantity of the product sold.
- Sales: The sales amount.
- Cost: The cost of the product.
- Profit: The profit made from the sale.
Step-by-Step Implementation
1. Import Necessary Libraries
First, we need to import the required libraries for data manipulation, visualization, and building the Random Forest model.
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder, StandardScaler
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score, classification_report2. Load the Dataset
Next, we load the dataset from the GitHub repository.
url = 'https://raw.githubusercontent.com/gustiyaniz/Random-Forest-Classifier-Predict-Label-Product-Implemented-in-Python/main/salesdatades23.csv'
data = pd.read_csv(url, sep=",", header=0)
data['Date'] = pd.to_datetime(data['Date'], format='%m/%d/%Y')
print('Shape of dataframe:', data.shape)
data.head()
3. Exploratory Data Analysis (EDA)
Perform some basic EDA to understand the structure of the dataset.
# Basic statistics of the dataset
data.describe()
import matplotlib.pyplot as plt
import seaborn as sns
# Get the top 10 products by count
top_10_products = data['Product'].value_counts().nlargest(10).index
# Filter the data to include only the top 10 products
top_10_data = data[data['Product'].isin(top_10_products)]
# Distribution of the top 10 products
plt.figure(figsize=(12, 6))
sns.countplot(y='Product', data=top_10_data, order=top_10_products)
plt.title('Distribution of Top 10 Products')
plt.xlabel('Count')
plt.ylabel('Product')
4. Encode Product Labels
Encode the product names using LabelEncoder.
label_encoder = LabelEncoder()
data['product_encoded'] = label_encoder.fit_transform(data['Product'])
data.head()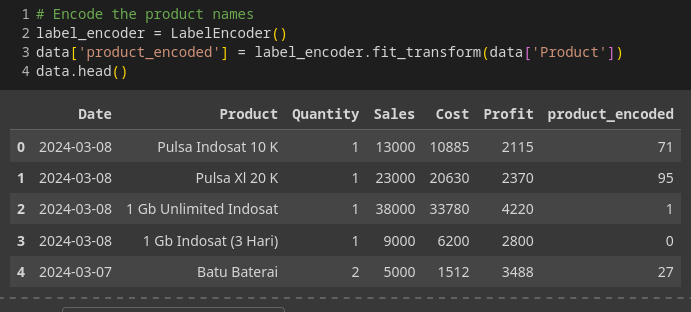
5. Extract Features and Labels
Extract features and labels for the model.
features = data[['Date', 'Quantity', 'Sales', 'Profit', 'Cost']]
labels = data['product_encoded']
# Extract date features
features['day'] = data['Date'].dt.day
features['month'] = data['Date'].dt.month
features['year'] = data['Date'].dt.year
features['dayofweek'] = data['Date'].dt.dayofweek
# Drop the original date column
features = features.drop(columns=['Date'])
features.head()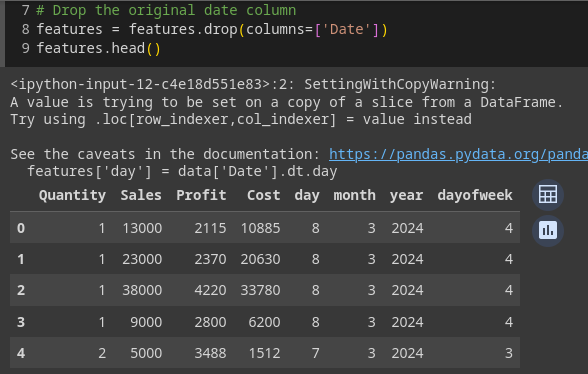
6. Normalize Numerical Features
Normalize the numerical features using StandardScaler.
scaler = StandardScaler()
features[['Quantity', 'Sales', 'Profit', 'Cost']] = scaler.fit_transform(features[['Quantity', 'Sales', 'Profit', 'Cost']])7. Split the Dataset
Split the data into training and testing sets.
X_train, X_test, y_train, y_test = train_test_split(features, labels, test_size=0.2, random_state=42)8. Build the Random Forest Model
Create and train the Random Forest classifier.
# Initialize the model
model = RandomForestClassifier(n_estimators=200, random_state=42)
# Train the model
model.fit(X_train, y_train)
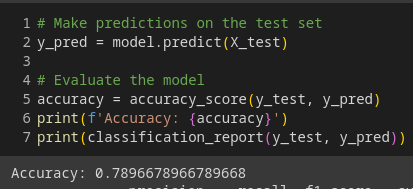
# Make predictions on the test set
y_pred = model.predict(X_test)
# Evaluate the model
accuracy = accuracy_score(y_test, y_pred)
print(f'Accuracy: {accuracy}')
print(classification_report(y_test, y_pred))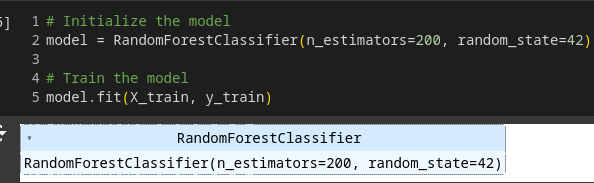
9. Predict Missing Labels
Load new data and preprocess it for prediction.
# Load new data without product names
path = 'https://raw.githubusercontent.com/gustiyaniz/Random-Forest-Classifier-Predict-Label-Product-Implemented-in-Python/main/SalesPredict.csv'
new_data = pd.read_csv(path, sep=",", header=0)
new_data['Date'] = pd.to_datetime(new_data['Date'], format='%m/%d/%Y')
new_data = new_data[['Date', 'Quantity', 'Sales', 'Profit', 'Cost']]
# Preprocess the new data
new_data['day'] = new_data['Date'].dt.day
new_data['month'] = new_data['Date'].dt.month
new_data['year'] = new_data['Date'].dt.year
new_data['dayofweek'] = new_data['Date'].dt.dayofweek
new_data = new_data.drop(columns=['Date'])
new_data[['Quantity', 'Sales', 'Profit', 'Cost']] = scaler.transform(new_data[['Quantity', 'Sales', 'Profit', 'Cost']])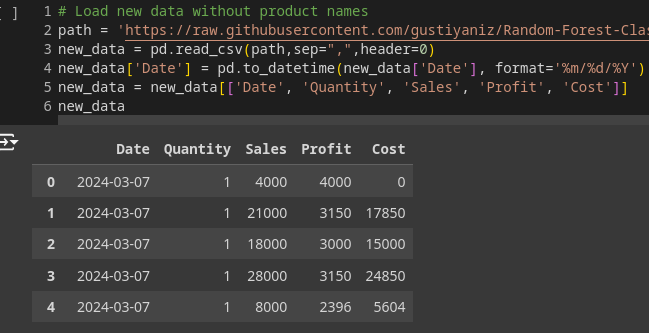
Predict the product names for the new data.
# Predict the product names for the new data
predictions = model.predict(new_data)
# Decode the product names
predicted_products = label_encoder.inverse_transform(predictions)
# Add the predicted product names to the new data
new_data['predicted_product'] = predicted_products
print(new_data)
datapredict = pd.read_csv(path, sep=",", header=0)
datapredict['predicted_product'] = predicted_products
print(datapredict)
# Save the results to a CSV file
output_csv_file = "predictproduct.csv"
datapredict.to_csv(output_csv_file, index=False)
Conclusion
By utilizing the Random Forest classifier, we successfully predicted the missing product labels in our sales data, ensuring the dataset is complete and reliable for further analysis. This approach can be extended to other types of missing data, providing a robust solution for data cleaning and preparation.
Feel free to check out the complete code and dataset on my GitHub repository and my Google Colab notebook. Happy coding!