Exploring Diabetes Patient Analysis with MySQL

Introduction
As a Data Analyst Intern at Psyliq, I have the incredible opportunity to apply my skills in a real-world setting, contributing to projects that make a meaningful impact. This article is a showcase of one such project, where I explore the complexities of diabetes patient records using MySQL. Throughout this project, I leveraged Visual Studio Code along with the MySQL shell extension, enhancing the analytical process and providing a more comprehensive analysis of the data.
Project Setup
Database Creation
The foundation of our analysis lies in the creation of a dedicated MySQL database. Let’s call it diabetes.
CREATE DATABASE diabetes;
USE diabetes;
Patient Table
Next, we create a table named diabetes_data to store essential information about diabetes patients.
CREATE TABLE diabetes_data(
EmployeeName VARCHAR(255),
Patient_id VARCHAR(255),
gender VARCHAR(10),
age INT,
hypertension INT,
heart_disease INT,
smoking_history VARCHAR(50),
bmi DECIMAL(5,2),
HbA1c_level DECIMAL(4,1),
blood_glucose_level INT,
diabetes INT
);
DESCRIBE diabetes_data;

Data Import
With our database and table in place, it’s time to inject some life into our analysis by importing CSV file into the diabetes_data table.
LOAD DATA INFILE '/var/lib/mysql-files/diabetes.csv'
INTO TABLE diabetes_data
FIELDS TERMINATED BY ','
ENCLOSED BY '"'
LINES TERMINATED BY '\n'
IGNORE 1 ROWS;
SELECT * FROM diabetes_data
LIMIT 100;
Analysis Queries
Now that our data is ready, let’s embark on the journey of extracting insights from the dataset.
Query 1: Retrieve the Patient_id and ages of all patients
-- 1. Retrieve the Patient_id and ages of all patients
SELECT Patient_id, age
FROM diabetes_data;
Query 2: Select all female patients who are older than 40
-- 2. Select all female patients who are older than 40.
SELECT Patient_id, EmployeeName, gender, age
FROM diabetes_data
WHERE gender = 'female' AND age > 40;
Query 3: Calculate the average BMI of patients
SELECT AVG(bmi) AS Average_BMI
FROM diabetes_data;
Query 4: List patients in descending order of blood glucose levels
-- 4. List patients in descending order of blood glucose levels.
SELECT Patient_id, EmployeeName, blood_glucose_level
FROM diabetes_data
ORDER BY blood_glucose_level DESC;
Query 5: Find patients who have hypertension and diabetes
SELECT *
FROM diabetes_data
WHERE hypertension = 1 AND diabetes = 1
ORDER BY EmployeeName;
Query 6: Determine the number of patients with heart disease
-- 6. Determine the number of patients with heart disease.
SELECT COUNT(*) AS Total_Heart_Disease
FROM diabetes_data
WHERE heart_disease = 1;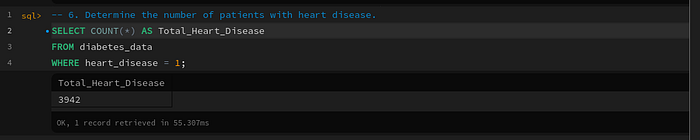
Query 7: Group patients by smoking history
-- 7. Group patients by smoking history and count how many smokers and non-smokers there are.
SELECT smoking_history, COUNT(*) AS patient_count
FROM diabetes_data
GROUP BY smoking_history;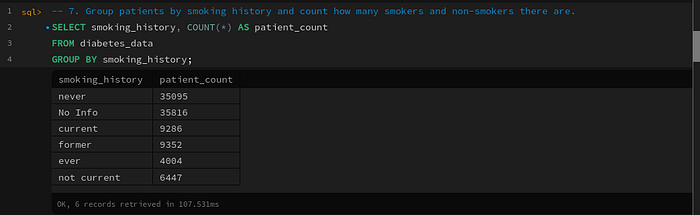
Query 8: Retrieve the Patient_ids of patients who have a BMI greater than the average BMI
-- 8. Retrieve the Patient_ids of patients who have a BMI greater than the average BMI
SELECT Patient_id, bmi
FROM diabetes_data
WHERE bmi > (SELECT AVG(bmi) FROM diabetes_data);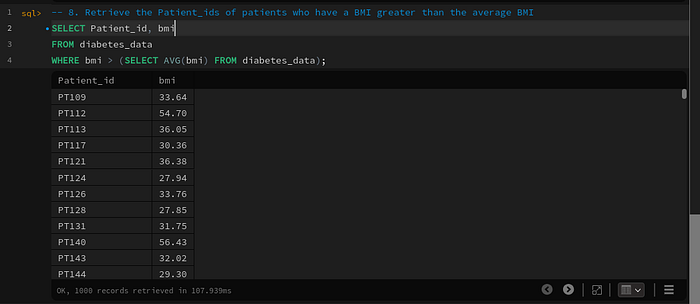
Query 9: Find the patient with the highest HbA1c level and the patient with the lowest HbA1clevel
-- 9. Find the patient with the highest HbA1c level and the patient with the lowest HbA1clevel.
-- Highest HbA1c level
SELECT *
FROM diabetes_data
ORDER BY HbA1c_level DESC
LIMIT 1;
-- Lowest HbA1c level
SELECT *
FROM diabetes_data
ORDER BY HbA1c_level ASC
LIMIT 1;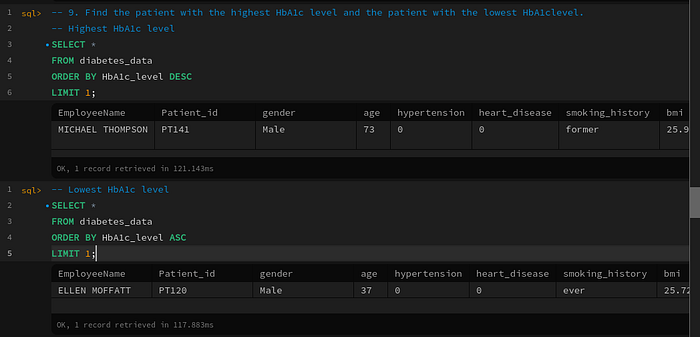
Query 10: Calculate the age of patients in years (assuming the current date as of now)
-- 10. Calculate the age of patients in years (assuming the current date as of now).
SELECT EmployeeName, Patient_id,
YEAR(NOW()) - age AS Birth_Years,
YEAR(NOW()) - YEAR(NOW()) + age AS current_age
FROM diabetes_data;
Query 11: Rank patients by blood glucose level within each gender group
-- 11. Rank patients by blood glucose level within each gender group.
SELECT
Patient_id,
gender,
blood_glucose_level,
RANK() OVER (PARTITION BY gender ORDER BY blood_glucose_level) AS glucose_level_rank
FROM diabetes_data;
Query 12: Update the smoking history of patients who are older than 50 to “Ex-smoker”
-- 12. Update the smoking history of patients who are older than 50 to "Ex-smoker."
UPDATE diabetes_data
SET smoking_history = 'Ex-smoker'
WHERE age > 50;
Query 13: Insert a new patient into the database with sample data
-- 13. Insert a new patient into the database with sample data.
INSERT INTO diabetes_data (EmployeeName, Patient_id, gender, age, hypertension, heart_disease, smoking_history, bmi, HbA1c_level, blood_glucose_level, diabetes)
VALUES
('Alex Doe', 'PT188882', 'Male', 35, 0, 0, 'current', 26.5, 6.0, 120, 0),
('Justiyen', 'PT111111', 'Male', 25, 0, 0, 'current', 20.5, 5.0, 110, 0);
Query 14: Delete all patients with heart disease from the database
-- 14. Delete all patients with heart disease from the database.
DELETE FROM diabetes_data
WHERE heart_disease = 1;
Query 15: Find patients who have hypertension but not diabetes using the EXCEPT operator
-- 15. Find patients who have hypertension but not diabetes using the EXCEPT operator.
SELECT *
FROM diabetes_data AS d1
WHERE hypertension = 1 AND NOT EXISTS (
SELECT 1
FROM diabetes_data AS d2
WHERE d1.Patient_id = d2.Patient_id AND d2.diabetes = 1
);
Query 16: Define a unique constraint on the “patient_id” column to ensure its values are unique
-- 16. Define a unique constraint on the "patient_id" column to ensure its values are unique.
ALTER TABLE diabetes_data
ADD CONSTRAINT unique_patient_id UNIQUE (Patient_id);
Query 17: Create a view that displays the Patient_ids, ages, and BMI of patients
-- 17. Create a view that displays the Patient_ids, ages, and BMI of patients.
CREATE VIEW patient_view AS
SELECT Patient_id, age, bmi
FROM diabetes_data;
SELECT * FROM patient_view;
Enhancing Diabetes Database Schema
The current diabetes database schema exhibits a solid foundation, yet there’s room for optimization. Let’s explore some key suggestions to elevate its structure:
1. Normalization for Efficient Data Storage:
Splitting Patient Information:
Consider breaking down patient information into separate tables to avoid redundant data. For example, you might create a patients table to store general patient details (name, gender, age) and a health_metrics table to store health-related information.
CREATE TABLE patients (
patient_id INT PRIMARY KEY AUTO_INCREMENT,
patient_name VARCHAR(255),
gender VARCHAR(10),
age INT
);
CREATE TABLE health_metrics (
patient_id INT,
hypertension INT,
heart_disease INT,
smoking_history VARCHAR(50),
bmi DECIMAL(5,2),
hba1c_level DECIMAL(4,1),
blood_glucose_level INT,
diabetes INT,
FOREIGN KEY (patient_id) REFERENCES patients(patient_id)
);
2. Use Enumerations for Categorical Data:
Smoking History:
Utilize an enumeration for the smoking_history column to ensure consistent values and enhance data integrity.
CREATE TABLE health_metrics (
...
smoking_history ENUM('never', 'current', 'former', 'No Info'),
...
);3. Data Validation for Precision:
Age and Health Metrics:
Implement constraints or triggers to ensure age and health metrics fall within reasonable ranges, promoting accurate and reliable data.
CREATE TABLE health_metrics (
...
age INT CHECK (age > 0 AND age < 150),
bmi DECIMAL(5,2) CHECK (bmi >= 0),
hba1c_level DECIMAL(4,1) CHECK (hba1c_level >= 0),
blood_glucose_level INT CHECK (blood_glucose_level >= 0),
...
);4. Documentation for Clarity:
Document relationships, foreign keys, and constraints to facilitate understanding for future developers working with the schema.
5. Primary Key Usage:
Ensure each table has a primary key for unique record identification. In the provided schema, patient_id serves this purpose.
6. Constraints for Data Integrity:
Add appropriate constraints, such as foreign key constraints, to maintain referential integrity between tables.
7. Review and Refine Data Types:
Evaluate and refine data types to ensure they align optimally with the nature of the stored data.
Optimizing SQL Query Performance
Optimizing the performance of SQL queries on the diabetes dataset involves various strategies to enhance efficiency and reduce query execution times. Here are some key considerations and optimization techniques:
1. Indexing for Query Optimization:
Indexing Columns:
Identify frequently queried columns and add indexes to enhance query performance.
CREATE INDEX idx_patient_name ON patients(patient_name);
CREATE INDEX idx_blood_glucose ON health_metrics(blood_glucose_level);2. Use of EXPLAIN:
The EXPLAIN statement is our detective tool for dissecting query execution plans. By analyzing the execution plan, we gain insights into how the database engine intends to retrieve data. This knowledge is invaluable for identifying potential bottlenecks and fine-tuning queries for optimal efficiency.
EXPLAIN SELECT * FROM health_metrics WHERE diabetes = 1;3. SELECTive Retrieval for Precision
When crafting SELECT statements, be mindful of the columns you truly need. Instead of opting for SELECT *, selectively retrieve only the necessary fields. This reduces data transfer volumes and, consequently, speeds up query execution.
SELECT patient_id, patient_name FROM patients WHERE age > 50;4. Avoid SELECT DISTINCT:
While SELECT DISTINCT is a powerful tool, it can be resource-intensive. Be cautious of its usage, and explore alternative approaches if possible. This ensures that you achieve the desired result without compromising performance.
5. Limiting Results with LIMIT:
For queries that potentially return large result sets, consider using the LIMIT clause to restrict the number of rows returned. This is particularly beneficial for paginated displays and can significantly enhance query performance.
SELECT * FROM patients LIMIT 10;6. Proper Use of Joins:
Optimize JOIN operations by ensuring joined columns are indexed. Choose the appropriate join types (INNER JOIN, LEFT JOIN) based on the specific requirements of your query.
SELECT * FROM patients
INNER JOIN health_metrics ON patients.patient_id = health_metrics.patient_id;7. Partitioning for Scale
As your dataset grows, partitioning tables based on certain criteria, such as date ranges, can be a game-changer. This technique enhances query performance, particularly for time-series data.
8. Harnessing the Power of Caching
Leverage caching mechanisms at the database or application level to store frequently used query results. Caching is a valuable strategy for queries involving relatively static data.
9. Regular Maintenance for Longevity
Schedule regular maintenance tasks, including index rebuilding and database statistics updating. This ensures optimal performance over time and prevents performance degradation.
10. Parameterized Queries for Security and Efficiency
Embrace parameterized queries to safeguard against SQL injection risks and improve the efficiency of query execution plans, especially for frequently reused queries with different parameter values.
Conclusion
In our exploration of diabetes patient data with MySQL, we’ve journeyed through the realms of analysis, schema improvement, and query optimization. From unraveling insights in patient records to sculpting a more efficient database structure and fine-tuning SQL queries, each step contributes to a more insightful and responsive data experience. This chapter isn’t just about numbers and queries; it’s a commitment to efficiency, precision, and the continual pursuit of understanding within the vast landscape of healthcare data. Here’s to the stories yet to be uncovered and the transformative power of data exploration!
